Execute full model bootstrapping with ALE calculation on each bootstrap run
Source:R/model_bootstrap.R
model_bootstrap.RdNo modelling results, with or without ALE, should be considered reliable without
being bootstrapped. For large datasets, normally the model provided to ale()
is the final deployment model that has been validated and evaluated on
training and testing on subsets; that is why ale() is calculated on the full
dataset. However, when a dataset is too small to be subdivided into training
and test sets for a standard machine learning process, then the entire model
should be bootstrapped. That is, multiple models should be trained, one on
each bootstrap sample. The reliable results are the average results of all
the bootstrap models, however many there are. For details, see the vignette
on small datasets or the details and examples below.
model_bootstrap() automatically carries out full-model bootstrapping suitable
for small datasets. Specifically, it:
Creates multiple bootstrap samples (default 100; the user can specify any number);
Creates a model on each bootstrap sample;
Calculates model overall statistics, variable coefficients, and ALE values for each model on each bootstrap sample;
Calculates the mean, median, and lower and upper confidence intervals for each of those values across all bootstrap samples.
Usage
model_bootstrap(
data,
model,
...,
model_call_string = NULL,
model_call_string_vars = character(),
parallel = future::availableCores(logical = FALSE, omit = 1),
model_packages = NULL,
y_col = NULL,
binary_true_value = TRUE,
pred_fun = function(object, newdata, type = pred_type) {
stats::predict(object =
object, newdata = newdata, type = type)
},
pred_type = "response",
boot_it = 100,
seed = 0,
boot_alpha = 0.05,
boot_centre = "mean",
output = c("ale", "model_stats", "model_coefs"),
ale_options = list(),
tidy_options = list(),
glance_options = list(),
silent = FALSE
)Arguments
- data
dataframe. Dataset that will be bootstrapped.
- model
See documentation for
ale()- ...
not used. Inserted to require explicit naming of subsequent arguments.
- model_call_string
character string. If NULL,
model_bootstrap()tries to automatically detect and construct the call for bootstrapped datasets. If it cannot, the function will fail early. In that case, a character string of the full call for the model must be provided that includesboot_dataas the data argument for the call. See examples.- model_call_string_vars
character. Character vector of names of variables included in
model_call_stringthat are not columns indata. If any such variables exist, they must be specified here or else parallel processing will produce an error. If parallelization is disabled withparallel = 0, then this is not a concern.- parallel
See documentation for
ale()- model_packages
See documentation for
ale()- y_col, pred_fun, pred_type
See documentation for
ale(). Only used to calculate bootstrapped performance measures. If NULL (default), then the relevant performance measures are calculated only if these arguments can be automatically detected.- binary_true_value
any single atomic value. If the model represented by
modelormodel_call_stringis a binary classification model,binary_true_valuespecifies the value ofy_col(the target outcome) that is consideredTRUE; any other value ofy_colis consideredFALSE. This argument is ignored if the model is not a binary classification model. For example, if 2 meansTRUEand 1 meansFALSE, then setbinary_true_valueas2.- boot_it
integer from 0 to Inf. Number of bootstrap iterations. If boot_it = 0, then the model is run as normal once on the full
datawith no bootstrapping.- seed
integer. Random seed. Supply this between runs to assure identical bootstrap samples are generated each time on the same data.
- boot_alpha
numeric. The confidence level for the bootstrap confidence intervals is 1 - boot_alpha. For example, the default 0.05 will give a 95% confidence interval, that is, from the 2.5% to the 97.5% percentile.
- boot_centre
See See documentation for
ale()- output
character vector. Which types of bootstraps to calculate and return:
'ale': Calculate and return bootstrapped ALE data and plot.
'model_stats': Calculate and return bootstrapped overall model statistics.
'model_coefs': Calculate and return bootstrapped model coefficients.
'boot_data': Return full data for all bootstrap iterations. This data will always be calculated because it is needed for the bootstrap averages. By default, it is not returned except if included in this
outputargument.
- ale_options, tidy_options, glance_options
list of named arguments. Arguments to pass to the
ale(),broom::tidy(), orbroom::glance()functions, respectively, beyond (or overriding) the defaults. In particular, to obtain p-values for ALE statistics, see the details.- silent
See documentation for
ale()
Value
list with the following elements (depending on values requested in the output argument:
model_stats: tibble of bootstrapped results frombroom::glance()boot_valid: named vector of advanced model performance measures; these are bootstrap-validated with the .632 correction (NOT the .632+ correction):mae: mean absolute error (bootstrap validated)
mad: mean absolute deviation about the mean (this is a descriptive statistic calculated on the full dataset; it is provided for reference)
sa_mae_mad: standardized accuracy of the MAE referenced on the MAD (bootstrap validated)
rmse: root mean squared error (bootstrap validated)
standard deviation (this is a descriptive statistic calculated on the full dataset; it is provided for reference)
sa_rmse_sd: standardized accuracy of the RMSE referenced on the SD (bootstrap validated)
model_coefs: tibble of bootstrapped results frombroom::tidy()ale: list of bootstrapped ALE resultsdata: ALE data (seeale()for details about the format)stats: ALE statistics. The same data is duplicated with different views that might be variously useful:by_term: statistic, estimate, conf.low, median, mean, conf.high. ("term" means variable name.) The column names are compatible with thebroompackage. The confidence intervals are based on theale()function defaults; they can be changed with theale_optionsargument. The estimate is the median or the mean, depending on theboot_centreargument.by_stat: term, estimate, conf.low, median, mean, conf.high.estimate: term, then one column per statistic provided with the default estimate. This view does not present confidence intervals.
plots: ALE plots (seeale()for details about the format)
boot_data: full bootstrap data (not returned by default)other values: the
boot_it,seed,boot_alpha, andboot_centrearguments that were originally passed are returned for reference.
p-values
The broom::tidy() summary statistics will provide p-values. However, the procedure for obtaining p-values for ALE statistics is very slow: it involves retraining the model 1000 times. Thus, it is not efficient to calculate p-values on every execution of model_bootstrap(). Although the ale() function provides an 'auto' option for creating p-values, that option is disabled in model_bootstrap() because it would be far too slow: it would involve retraining the model 1000 times the number of bootstrap iterations. Rather, you must first create a p-values distribution object using the procedure described in help(create_p_dist). If the name of your p-values object is p_dist, you can then request p-values each time you run model_bootstrap() by passing it the argument ale_options = list(p_values = p_dist).
References
Okoli, Chitu. 2023. “Statistical Inference Using Machine Learning and Classical Techniques Based on Accumulated Local Effects (ALE).” arXiv. https://arxiv.org/abs/2310.09877.
Examples
# attitude dataset
attitude
#> rating complaints privileges learning raises critical advance
#> 1 43 51 30 39 61 92 45
#> 2 63 64 51 54 63 73 47
#> 3 71 70 68 69 76 86 48
#> 4 61 63 45 47 54 84 35
#> 5 81 78 56 66 71 83 47
#> 6 43 55 49 44 54 49 34
#> 7 58 67 42 56 66 68 35
#> 8 71 75 50 55 70 66 41
#> 9 72 82 72 67 71 83 31
#> 10 67 61 45 47 62 80 41
#> 11 64 53 53 58 58 67 34
#> 12 67 60 47 39 59 74 41
#> 13 69 62 57 42 55 63 25
#> 14 68 83 83 45 59 77 35
#> 15 77 77 54 72 79 77 46
#> 16 81 90 50 72 60 54 36
#> 17 74 85 64 69 79 79 63
#> 18 65 60 65 75 55 80 60
#> 19 65 70 46 57 75 85 46
#> 20 50 58 68 54 64 78 52
#> 21 50 40 33 34 43 64 33
#> 22 64 61 52 62 66 80 41
#> 23 53 66 52 50 63 80 37
#> 24 40 37 42 58 50 57 49
#> 25 63 54 42 48 66 75 33
#> 26 66 77 66 63 88 76 72
#> 27 78 75 58 74 80 78 49
#> 28 48 57 44 45 51 83 38
#> 29 85 85 71 71 77 74 55
#> 30 82 82 39 59 64 78 39
## ALE for general additive models (GAM)
## GAM is tweaked to work on the small dataset.
gam_attitude <- mgcv::gam(rating ~ complaints + privileges + s(learning) +
raises + s(critical) + advance,
data = attitude)
summary(gam_attitude)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> rating ~ complaints + privileges + s(learning) + raises + s(critical) +
#> advance
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 36.97245 11.60967 3.185 0.004501 **
#> complaints 0.60933 0.13297 4.582 0.000165 ***
#> privileges -0.12662 0.11432 -1.108 0.280715
#> raises 0.06222 0.18900 0.329 0.745314
#> advance -0.23790 0.14807 -1.607 0.123198
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(learning) 1.923 2.369 3.761 0.0312 *
#> s(critical) 2.296 2.862 3.272 0.0565 .
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> R-sq.(adj) = 0.776 Deviance explained = 83.9%
#> GCV = 47.947 Scale est. = 33.213 n = 30
# \donttest{
# Full model bootstrapping
# Only 4 bootstrap iterations for a rapid example; default is 100
# Increase value of boot_it for more realistic results
mb_gam <- model_bootstrap(
attitude,
gam_attitude,
boot_it = 4
)
# If the model is not standard, supply model_call_string with
# 'data = boot_data' in the string (not as a direct argument to [model_bootstrap()])
mb_gam <- model_bootstrap(
attitude,
gam_attitude,
model_call_string = 'mgcv::gam(
rating ~ complaints + privileges + s(learning) +
raises + s(critical) + advance,
data = boot_data
)',
boot_it = 4
)
# Model statistics and coefficients
mb_gam$model_stats
#> # A tibble: 9 × 7
#> name boot_valid conf.low median mean conf.high sd
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 df NA 15.2 18.5 18.3 20.9 2.50e+ 0
#> 2 df.residual NA 9.15 11.5 11.7 14.8 2.50e+ 0
#> 3 nobs NA 30 30 30 30 0
#> 4 adj.r.squared NA 1.00 1.00 1.00 1.00 1.93e-15
#> 5 npar NA 23 23 23 23 0
#> 6 mae 19.7 13.7 NA NA 58.4 2.20e+ 1
#> 7 sa_mae_mad 0.0639 -1.42 NA NA 0.268 8.09e- 1
#> 8 rmse 24.9 17.8 NA NA 76.9 2.98e+ 1
#> 9 sa_rmse_sd 0.0523 -1.66 NA NA 0.240 9.46e- 1
mb_gam$model_coefs
#> # A tibble: 2 × 6
#> term conf.low median mean conf.high std.error
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 s(learning) 6.92 7.63 7.77 8.85 0.874
#> 2 s(critical) 2.80 6.10 5.49 7.13 2.13
# Plot ALE
mb_gam_plots <- plot(mb_gam)
mb_gam_1D_plots <- mb_gam_plots$distinct$rating$plots[[1]]
patchwork::wrap_plots(mb_gam_1D_plots, ncol = 2)
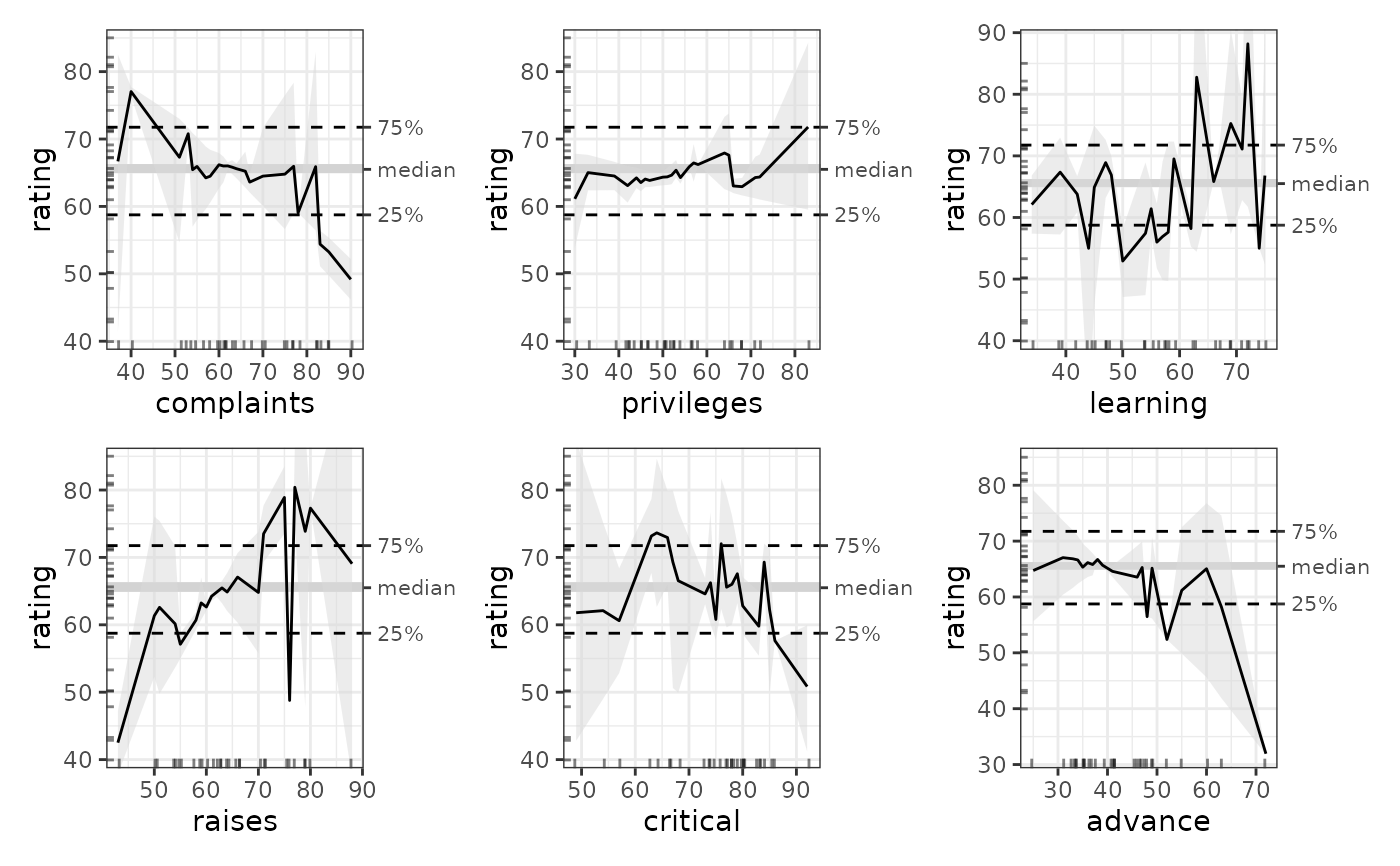 # }
# }