An ALE S7 object contains ALE data and statistics. For details, see vignette('ale-intro') or the details and examples below.
Usage
ALE(
model,
x_cols = list(d1 = TRUE),
data = NULL,
y_col = NULL,
...,
exclude_cols = NULL,
parallel = 0,
model_packages = NULL,
output_stats = TRUE,
output_boot_data = FALSE,
pred_fun = NULL,
pred_type = "response",
p_values = "auto",
require_same_p = TRUE,
aler_alpha = c(0.01, 0.05),
aled_fun = NULL,
max_num_bins = 10L,
fct_order = "levels",
boot_it = 0L,
boot_alpha = 0.05,
boot_centre = "mean",
seed = 0,
y_type = NULL,
sample_size = 500L,
silent = FALSE,
.bins = NULL
)Arguments
- model
model object. Required. Model for which ALE should be calculated. May be any kind of R object that can make predictions from data.
- x_cols, exclude_cols
character, list, or formula. Columns names from
datarequested in one of the specialx_colsformats for which ALE data is to be calculated. Defaults to 1D ALE for all columns indataexcepty_col. See details in the documentation forresolve_x_cols().- data
dataframe. Dataset from which to create predictions for the ALE. It should normally be the same dataset on which
modelwas trained. If not provided,ALE()will try to detect it automatically if it is included in themodelobject.- y_col
character(1). Name of the outcome target label (y) variable. If not provided,
ALE()will try to detect it automatically from themodelobject. If not found automatically,y_colshould be provided. For time-to-event (survival) models, see details.- ...
not used. Inserted to require explicit naming of subsequent arguments.
- parallel
non-negative integer(1) or character(1) in c("all", "all but one"). Number of parallel threads (workers or tasks) for parallel execution of the constructor. The default
parallel = 0disables parallel processing. "all but one" uses all available physical CPU cores minus one, reserved for the system, whereas "all" uses all physical and logical cores reported by the system. See details.- model_packages
character. Character vector of names of packages that
modeldepends on that might not be obvious with parallel processing. If you get weird error messages when parallel processing is enabled but they are resolved by settingparallel = 0, you might need to specifymodel_packages. See details.- output_stats
logical(1). If
TRUE(default), return ALE statistics.- output_boot_data
logical(1). If
TRUE, return the raw ALE data for each bootstrap iteration. Default isFALSE.- pred_fun, pred_type
function,character(1).
pred_funis a function that returns a vector of predicted values of typepred_typefrommodelondata. The defaultNULLforpred_funwill often work; if you get an error message, see details.- p_values
instructions for calculating p-values. Possible values are:
NULL: p-values are not calculated.An
ALEpDistobject: the object will be used to calculate p-values."auto"(default): If statistics are requested (output_stats = TRUE) and bootstrapping is requested (boot_it > 0), the constructor will try to automatically create a fast surrogateALEpDistobject; otherwise, no p-values are calculated. However, automatic creation of a surrogateALEpDistobject might not work with all R models. If the automatic process errors, then you must explicitly create and provide anALEpDist()object. Note: although faster surrogate p-values are convenient for interactive analysis, they are not acceptable for definitive conclusions or publication. See details below.
- require_same_p
logical(1). If
TRUE(default),p_valuesmust be generated with exactly the samemodelobject, even in the case of surrogate p-values. Only disable this option withFALSEif certain that a deliberate exception is appropriate, otherwise calculated p-values may be completely invalid. A notable valid exception is resampling the same model specification on various samples, such as with bootstrapping or cross-validation.- aler_alpha
numeric(2) from 0 to 1. Thresholds for p-values ("alpha") for confidence interval ranges for the ALER band if
p_valuesare provided (that is, notNULL). The inner band range will be the median value of y ±aler_alpha[2]of the relevant ALE statistic (usually ALE range or normalized ALE range). When there is a second outer band, its range will be the median ±aler_alpha[1]. For example, in the ALE plots, for the defaultaler_alpha = c(0.01, 0.05), the inner band will be the median ± ALER minimum or maximum at p = 0.05 and the outer band will be the median ± ALER minimum or maximum at p = 0.01.- aled_fun
character(1) in c("mad", "sd"), or NULL. Deviation function used to calculated ALE deviation.
"mad"is the mean absolute deviation;"sd"is the standard deviation. The defaultNULLwill normally use"mad"except if anALEpDistobject is provided forp_values; in that case, thealed_funis taken from theALEpDistobject.- max_num_bins
integer(1) > 1 or list. For numeric
x_cols, this sets an upper bound on the number of ALE bins, where actual bins are the lesser of the number of unique values andmax_num_bins. Valid formats are:Single integer > 1: used for all numeric
x_cols.List with overrides: a list with exactly two elements:
defaultis a single integer > 1 used as the default value;exceptis a named integer vector with values > 1 of per-column upper bounds. Unknown names are ignored with a warning. Non-numericx_cols(binary/ordinal/categorical) always use all observed levels. An example of the list format would bemax_num_bins = list(default = 10, except = c(wt = 25, carb = 4))
The default value of 10 is recommended for speed; it should adequately express most relationships. Increase it (e.g., to 100) for complex relationships. However, higher values are slower, especially for ALE interactions.
- fct_order
character(1) or list. Specifies how unordered factors and characters will be ordered for ALE calculation. (Ordered factors ignore this setting; they always use their intrinsic order.) The following options are possible:
"levels"(default): For ordered factors, use the order of the factor levels. Recommended for meaningful interpretation because this lets the user explicitly control their semantic sort order as desired. For characters, order unique values alphabetically."y_col": Sort based on the increasing mean values of the predictions ofy_colfor each factor level."ksd": Not recommended except for compatibility with the original ALEPlot reference implementation.List with overrides: a list with exactly two elements:
defaultis a character string with one of the above as the default value;exceptis a named character vector with per-column orderings. Unknown names trigger an error. An example of the list format would befct_order = list(default = "levels", except = c(continent = "y_col"))
See details.
- boot_it
non-negative integer(1). Number of bootstrap iterations for data-only bootstrapping on ALE data. This is appropriate for models that have been developed with cross-validation. For models that have not been validated, full-model bootstrapping should be used instead with a
ModelBoot()class object. See details there. The defaultboot_it = 0turns off bootstrapping.- boot_alpha
numeric(1) from 0 to 1. When ALE is bootstrapped (
boot_it > 0),boot_alphaspecifies the thresholds for p-values ("alpha") for percentile-based confidence interval range for the bootstrapped ALE values. The bootstrap confidence intervals will be the lowest and highest(1 - 0.05) / 2percentiles. For example, ifboot_alpha = 0.05(default), the confidence intervals will be from the 2.5 (low) and 97.5 (high) percentiles.- boot_centre
character(1) in c('mean', 'median'). When bootstrapping, the main estimate for the ALE y value is considered to be
boot_centre. Regardless of the value specified here, both the mean and median will be available.- seed
integer(1). Random seed. Supply this between runs to assure that identical random ALE data is generated each time when bootstrapping. Without bootstrapping, ALE is a deterministic algorithm that should result in identical results each time regardless of the seed specified. However, with parallel processing enabled, only the exact computing setup will give reproducible results. For reproducible results across different computers, leave parallelization disabled with
parallel = 0.- y_type
character(1) in c('binary', 'numeric', 'categorical', 'ordinal'). Datatype of the y (outcome) variable. Normally determined automatically; only provide if an error message for a complex model requires it.
- sample_size
non-negative integer(1). Size of the sample of
datato be returned with theALEobject. This is primarily used for rug plots inALEPlots().- silent
logical(1), default
FALSE.IfTRUE, do not display any non-essential messages during execution (such as progress bars). Regardless, any warnings and errors will always display. See details for how to customize progress bars.- .bins
Internal use only. List of ALE bin and n count vectors. If provided, these vectors will be used to set the intervals of the ALE x axis for each variable. By default (
NULL),ALE()automatically calculates the bins..binsis normally used in advanced analyses where the bins from a previous analysis are reused for subsequent analyses (for example, for full model bootstrapping withModelBoot()).
Properties
- effect
Stores the ALE data and, optionally, ALE statistics and bootstrap data for one or more categories.
- params
The parameters used to calculate the ALE data. These include most of the arguments used to construct the
ALEobject. These are either the values provided by the user or those used by default if the user did not change them but also includes several objects that are created within the constructor. These extra objects are described here, as well as those parameters that are stored differently from the form in the arguments:* `max_d`: the highest dimension of ALE data present. If only 1D ALE is present, then `max_d == 1`. If even one 2D ALE element is present (even with no 1D), then `max_d == 2`. * `requested_x_cols`,`ordered_x_cols`: `requested_x_cols` is the resolved list of `x_cols` as requested by the user (that is, `x_cols` minus `exclude_cols`). `ordered_x_cols` is the same set of `x_cols` but arranged in the internal storage order. * `y_cats`: categories for categorical classification models. For non-categorical models, this is the same as `y_col`. * `y_type`: high-level datatype of the y outcome variable. * `y_summary`: summary statistics of y values used for the ALE calculation. These statistics are based on the actual values of `y_col` unless if `y_type` is a probability or other value that is constrained in the `[0, 1]` range, in which case `y_summary` is based on the predictions of `y_col` from `model` on the `data`. `y_summary` is a named numeric matrix. For most outcomes with a single value per predicted row, there is just one column with the same name as `y_col`. For categorical y outcomes, there is one column for each category in `y_cats` plus an additional column with the same name as `y_col`; this is the mean of the categorical columns. The rows are named mostly as the percentile of the y values. E.g., the '5%' row is the 5th percentile of y values. The following named rows have special meanings: * `min`, `mean`, `max`: the minimum, mean, and maximum y values, respectively. Note that the median is `50%`, the 50th percentile. * `aler_lo_lo`, `aler_lo`, `aler_hi`, `aler_hi_hi`: When p-values are present, `aler_lo` and `aler_hi` are the inner lower and upper confidence intervals of `y_col` values with respect to the median (`50%`); `aler_lo_lo` and `aler_hi_hi` are the outer confidence intervals. See the documentation for the `aler_alpha` argument to understand how these are determined. Without p-values, these elements are absent. * `model`: selected elements that describe the `model` that the `ALE` object interprets. * `data`: selected elements that describe the `data` used to produce the `ALE` object. To avoid the large size of duplicating `data` entirely, only a sample of the size of the `sample_size` argument is retained. * `probs_inverted`: `TRUE` if the original probability values of the ALE object have been inverted using [invert_probs()]. `FALSE`, `NULL`, or absent otherwise.
Custom predict function
The calculation of ALE requires modifying several values of the original data. Thus, ALE() needs direct access to the predict function for the model. By default, ALE() uses a generic default predict function of the form predict(object, newdata, type) with the default prediction type of 'response'. If, however, the desired prediction values are not generated with that format, the user must specify what they want. Very often, the only modification needed is to change the prediction type to some other value by setting the pred_type argument (e.g., to 'prob' to generated classification probabilities). But if the desired predictions need a different function signature, then the user must create a custom prediction function and pass it to pred_fun. The requirements for this custom function are:
It must take three required arguments and nothing else:
object: a modelnewdata: a dataframe or compatible table type such as a tibble or data.tabletype: a string; it should usually be specified astype = pred_typeThese argument names are according to the R convention for the genericstats::predict()function.
It must return a vector or matrix of numeric values as the prediction.
You can see an example below of a custom prediction function.
ALE statistics and p-values
For details about the ALE-based statistics (ALED, ALER, NALED, and NALER), see vignette('ale-statistics'). For general details about the calculation of p-values, see ALEpDist(). Here, we clarify the automatic calculation of p-values with the ALE() constructor.
As explained in the documentation above for the p_values argument, the default p_values = "auto" will try to automatically create a fast surrogate ALEpDist object. However, this is on the condition that statistics are requested (default, output_stats = TRUE) and bootstrapping is also requested (not default, if boot_it is any value greater than 0). Requesting statistics is necessary otherwise p-values are not needed. However, the requirement for requiring bootstrapping is a pragmatic design choice. The challenge is that creating an ALEpDist object can be slow. (Even the fast surrogate option rarely takes less than 10 seconds, even with parallelization.) Thus, to optimize speed, p-values will not be calculated unless requested. However, if the user requests bootstrapping (which is slower than not requesting it), it can be assumed that they are willing to sacrifice some speed for the sake of greater precision in their ALE analysis; thus, extra time is taken to at least create a relatively faster surrogate ALEpDist object.
Parallel processing
Parallel processing is possible using the {furrr} framework. The number of parallel threads (workers or cores) is specified with the parallel argument. By default (parallel = 0), it is disabled. parallel = "all but one" will use all the available physical CPU cores except for one, reserved so that your computer does not slow down as you continue working on other tasks while the procedure runs. The parallel = "all" option will use all physical and logical CPU cores reported by the system, but the result might sometimes be slower if inappropriate allocation of these parallel processors chokes the system.
The {ale} package should be able to automatically recognize and load most packages that are needed, but with parallel processing enabled, some packages might not be properly loaded. This problem might be indicated if you get a strange error message that mentions something somewhere about "progress interrupted" or "future", especially if you see such errors after the progress bars begin displaying (assuming you did not disable progress bars with silent = TRUE). In that case, first try disabling parallel processing with parallel = 0. If that resolves the problem, then to get faster parallel processing to work, try adding all the package names needed for the model to the model_packages argument, e.g., model_packages = c('tidymodels', 'mgcv').
Time-to-event (survival) models
For time-to-event (survival) models, set the following arguments:
y_colmust be the set to the name of the binary event column.Include the time column in the
exclude_colsargument so that its ALE will not be calculated, e.g.,exclude_cols = 'time'. This is not essential but if it is not excluded, it will always result in an exactly zero ALE effect because time is an outcome, not a predictor, of the time-to-event model's outcome, so calculating it is a waste of time.pred_typemust be specified according to the desiredtypeargument for thepredict()method of the time-to-event algorithm (e.g., "risk", "survival", "time", etc.).pred_funmight work fine without modification as long as the settings above are configured. However, if there is an error with some time-to-event models, a custompred_funas specified above might be needed.
Progress bars
Progress bars are implemented with the {progressr} package. For details on customizing the progress bars, see the introduction to the {progressr} package. To disable progress bars when calling a function in the ale package, set silent = TRUE.
Sorting of unordered factors
The ALE algorithm requires an order for the values of all variables. All basic datatypes have a natural order except for unordered factors and characters. fct_order specifies how unordered factors will be ordered for ALE calculation. (Ordered factors ignore this setting; they always use their intrinsic order.) Note that factor ordering has no effect on the discriminativeness of the ALE algorithm; it only affects which level is listed first, second, and so on in comparison with each other, which is relevant for interpretation. The first level according to fct_order is always calculated as having zero effect; ALE for all other levels are relative to the first level. We recommend that users explicitly set the levels of each factor in an order that is meaningful for interpretation and then leave fct_order at its default value ("levels").
Character columns treat their unique values as factor levels. With fct_order = "levels", the order of values is alphabetical to make it easier to find results in plots.
An alternative ordering is to set fct_order = "y_col", which sorts levels based on the increasing mean values of the predictions of y_col for each factor level. Thus, the ALE results show how the isolated effects of each level of a factor might differ from the average effects when all other variables come into play.
The original ALEPlot reference implementation sorts factor levels based on their similarity to each other, using an algorithm based on Kolmogorov-Smirnov distances and multidimensional scaling. However, that implementation calculates distances using all the data that happen to be in the dataset, even if some of that data is not used in the model at all. This results in arbitrary different sort orders unless all columns not used in the model are excluded from the dataset. We do not recommend this approach, but we include it with the "ksd" option for compatibility with the original ALEPlot reference implementation.
References
Okoli, Chitu. 2023. “Statistical Inference Using Machine Learning and Classical Techniques Based on Accumulated Local Effects (ALE).” arXiv. doi:10.48550/arXiv.2310.09877.
Examples
# Load diamonds dataset with some cleanup
library(dplyr)
#>
#> Attaching package: ‘dplyr’
#> The following objects are masked from ‘package:stats’:
#>
#> filter, lag
#> The following objects are masked from ‘package:base’:
#>
#> intersect, setdiff, setequal, union
diamonds <- ggplot2::diamonds |>
filter(!(x == 0 | y == 0 | z == 0)) |>
# https://lorentzen.ch/index.php/2021/04/16/a-curious-fact-on-the-diamonds-dataset/
distinct(
price, carat, cut, color, clarity,
.keep_all = TRUE
) |>
rename(
x_length = x,
y_width = y,
z_depth = z,
depth_pct = depth
)
# Create a GAM model with flexible curves to predict diamond price
# Smooth all numeric variables and include all other variables
gam_diamonds <- mgcv::gam(
price ~ s(carat) + s(depth_pct) + s(table) + s(x_length) + s(y_width) + s(z_depth) +
cut + color + clarity,
data = diamonds
)
summary(gam_diamonds)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> price ~ s(carat) + s(depth_pct) + s(table) + s(x_length) + s(y_width) +
#> s(z_depth) + cut + color + clarity
#>
#> Parametric coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 4436.199 13.315 333.165 < 2e-16 ***
#> cut.L 263.124 39.117 6.727 1.76e-11 ***
#> cut.Q 1.792 27.558 0.065 0.948151
#> cut.C 74.074 20.169 3.673 0.000240 ***
#> cut^4 27.694 14.373 1.927 0.054004 .
#> color.L -2152.488 18.996 -113.313 < 2e-16 ***
#> color.Q -704.604 17.385 -40.528 < 2e-16 ***
#> color.C -66.839 16.366 -4.084 4.43e-05 ***
#> color^4 80.376 15.289 5.257 1.47e-07 ***
#> color^5 -110.164 14.484 -7.606 2.89e-14 ***
#> color^6 -49.565 13.464 -3.681 0.000232 ***
#> clarity.L 4111.691 33.499 122.742 < 2e-16 ***
#> clarity.Q -1539.959 31.211 -49.341 < 2e-16 ***
#> clarity.C 762.680 27.013 28.234 < 2e-16 ***
#> clarity^4 -232.214 21.977 -10.566 < 2e-16 ***
#> clarity^5 193.854 18.324 10.579 < 2e-16 ***
#> clarity^6 46.812 16.172 2.895 0.003799 **
#> clarity^7 132.621 14.274 9.291 < 2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Approximate significance of smooth terms:
#> edf Ref.df F p-value
#> s(carat) 8.695 8.949 37.027 < 2e-16 ***
#> s(depth_pct) 7.606 8.429 6.758 < 2e-16 ***
#> s(table) 5.759 6.856 3.682 0.000736 ***
#> s(x_length) 8.078 8.527 60.936 < 2e-16 ***
#> s(y_width) 7.477 8.144 211.202 < 2e-16 ***
#> s(z_depth) 9.000 9.000 16.266 < 2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> R-sq.(adj) = 0.929 Deviance explained = 92.9%
#> GCV = 1.2602e+06 Scale est. = 1.2581e+06 n = 39739
# \donttest{
# Simple ALE without bootstrapping: by default, all 1D ALE effects
# For speed, these examples use retrieve_rds() to load pre-created objects
# from an online repository.
# To run the code yourself, execute the code blocks directly.
serialized_objects_site <- "https://github.com/tripartio/ale/raw/main/download"
# Create ALE data
ale_gam_diamonds <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_gam_diamonds.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
# For models like mgcv::gam that store their data,
# there is no need to specify the data argument.
ALE(gam_diamonds)
}
)
# Simple printing of all plots
plot(ale_gam_diamonds)
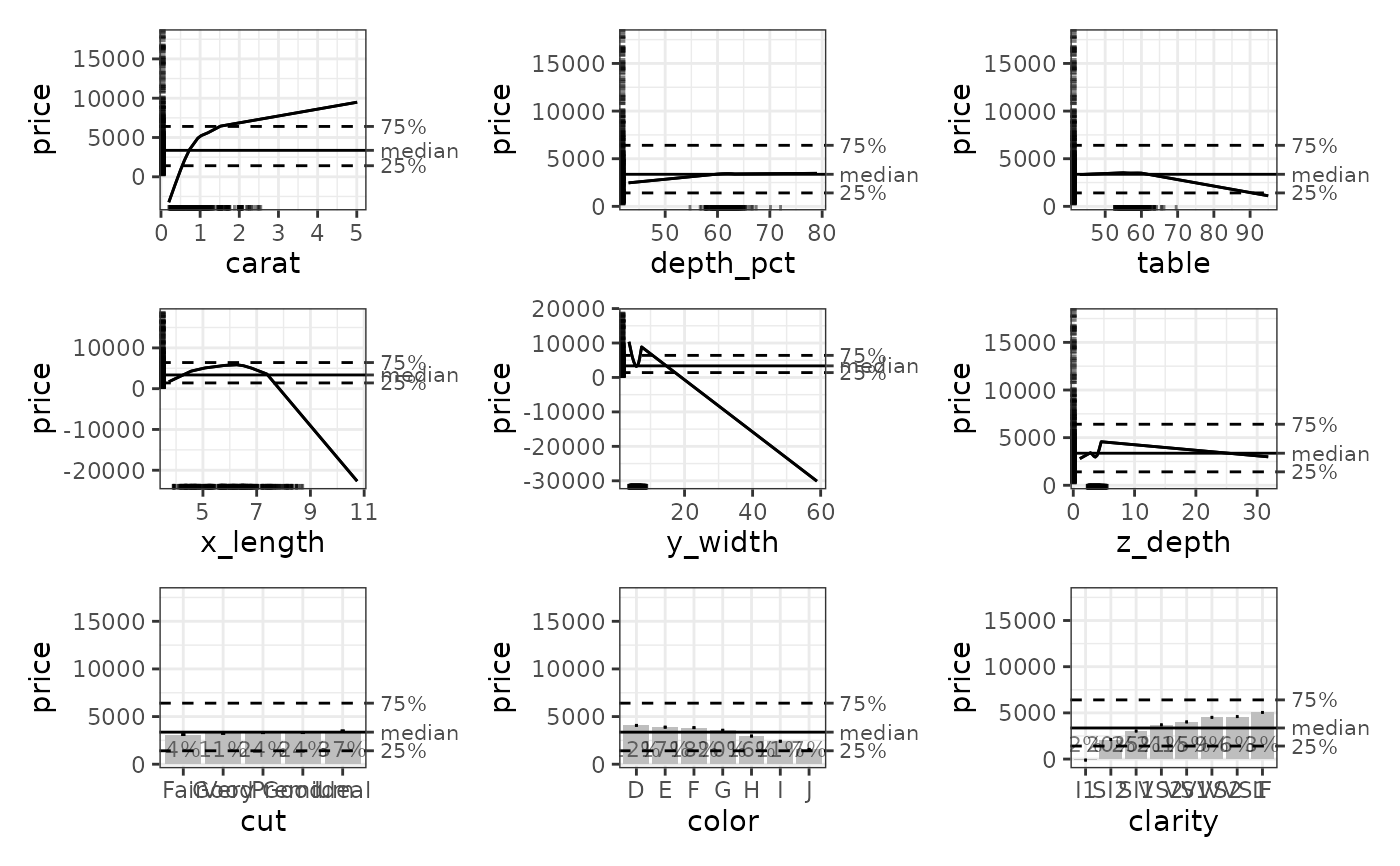 # Bootstrapped ALE
# This can be slow, since bootstrapping runs the algorithm boot_it times.
# In addition, bootstrapping automatically generates surrogate p-values by default.
# Create ALE with 100 bootstrap samples
ale_gam_diamonds_boot <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_gam_diamonds_boot.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
ALE(
gam_diamonds,
# request all 1D ALE effects and only the carat:clarity 2D effect
list(d1 = TRUE, d2 = 'carat:clarity'),
boot_it = 100
)
}
)
# saveRDS(ale_gam_diamonds_boot, file.choose())
# More advanced plot manipulation
ale_plots <- plot(ale_gam_diamonds_boot) # Create an ALEPlots object
# Print the plots: First page prints 1D ALE; second page prints 2D ALE
ale_plots # or print(ale_plots) to be explicit
# Bootstrapped ALE
# This can be slow, since bootstrapping runs the algorithm boot_it times.
# In addition, bootstrapping automatically generates surrogate p-values by default.
# Create ALE with 100 bootstrap samples
ale_gam_diamonds_boot <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_gam_diamonds_boot.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
ALE(
gam_diamonds,
# request all 1D ALE effects and only the carat:clarity 2D effect
list(d1 = TRUE, d2 = 'carat:clarity'),
boot_it = 100
)
}
)
# saveRDS(ale_gam_diamonds_boot, file.choose())
# More advanced plot manipulation
ale_plots <- plot(ale_gam_diamonds_boot) # Create an ALEPlots object
# Print the plots: First page prints 1D ALE; second page prints 2D ALE
ale_plots # or print(ale_plots) to be explicit
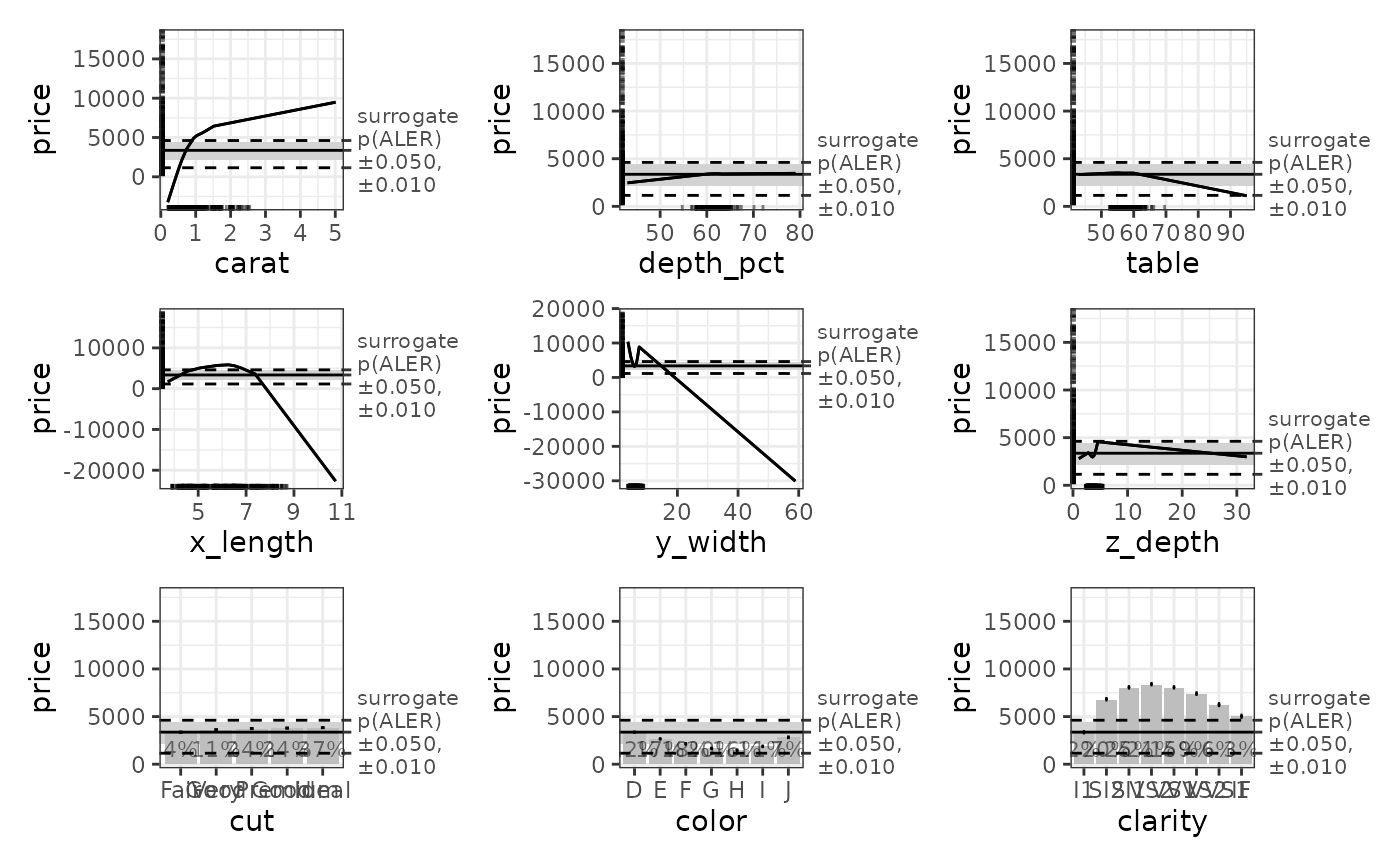
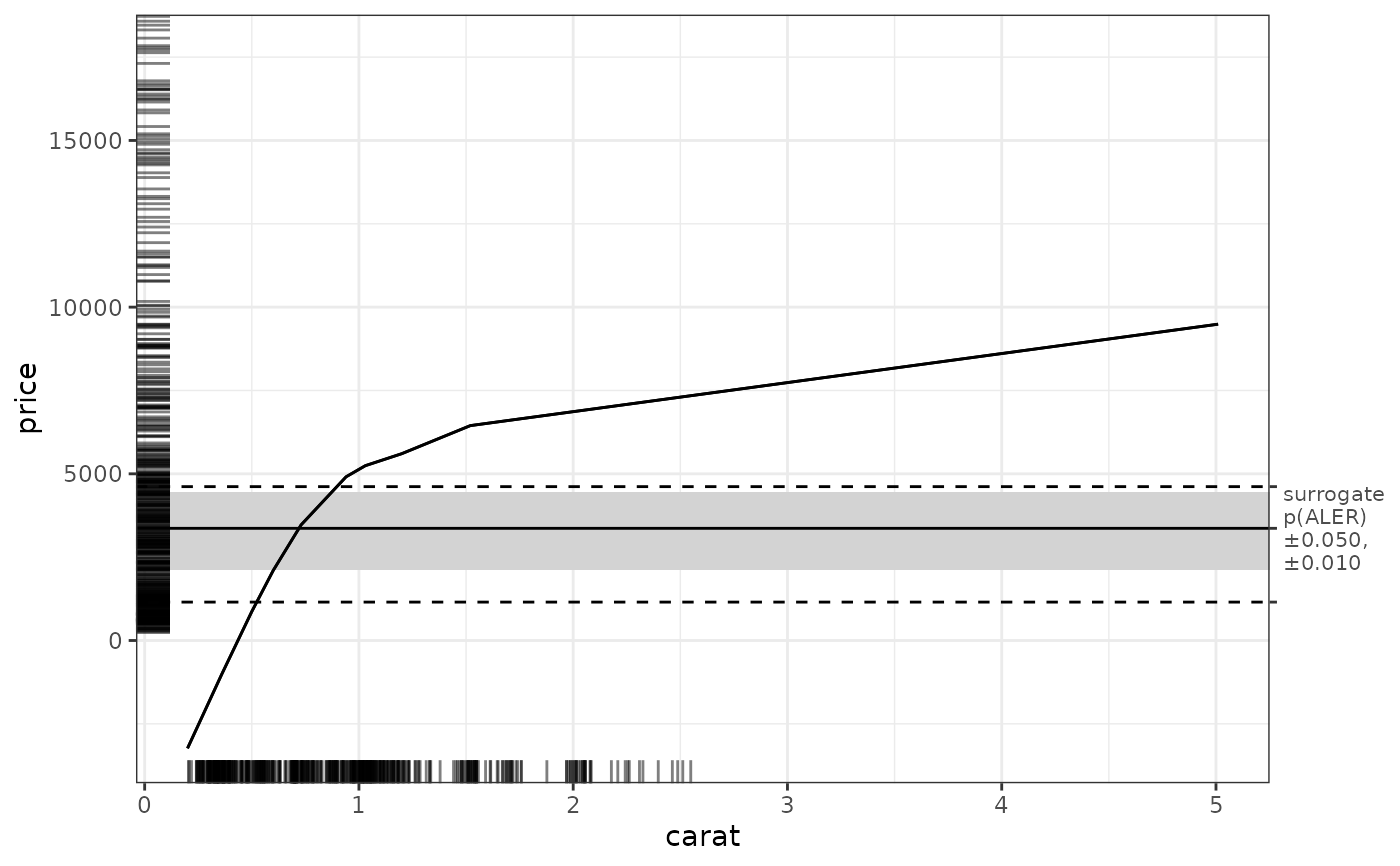
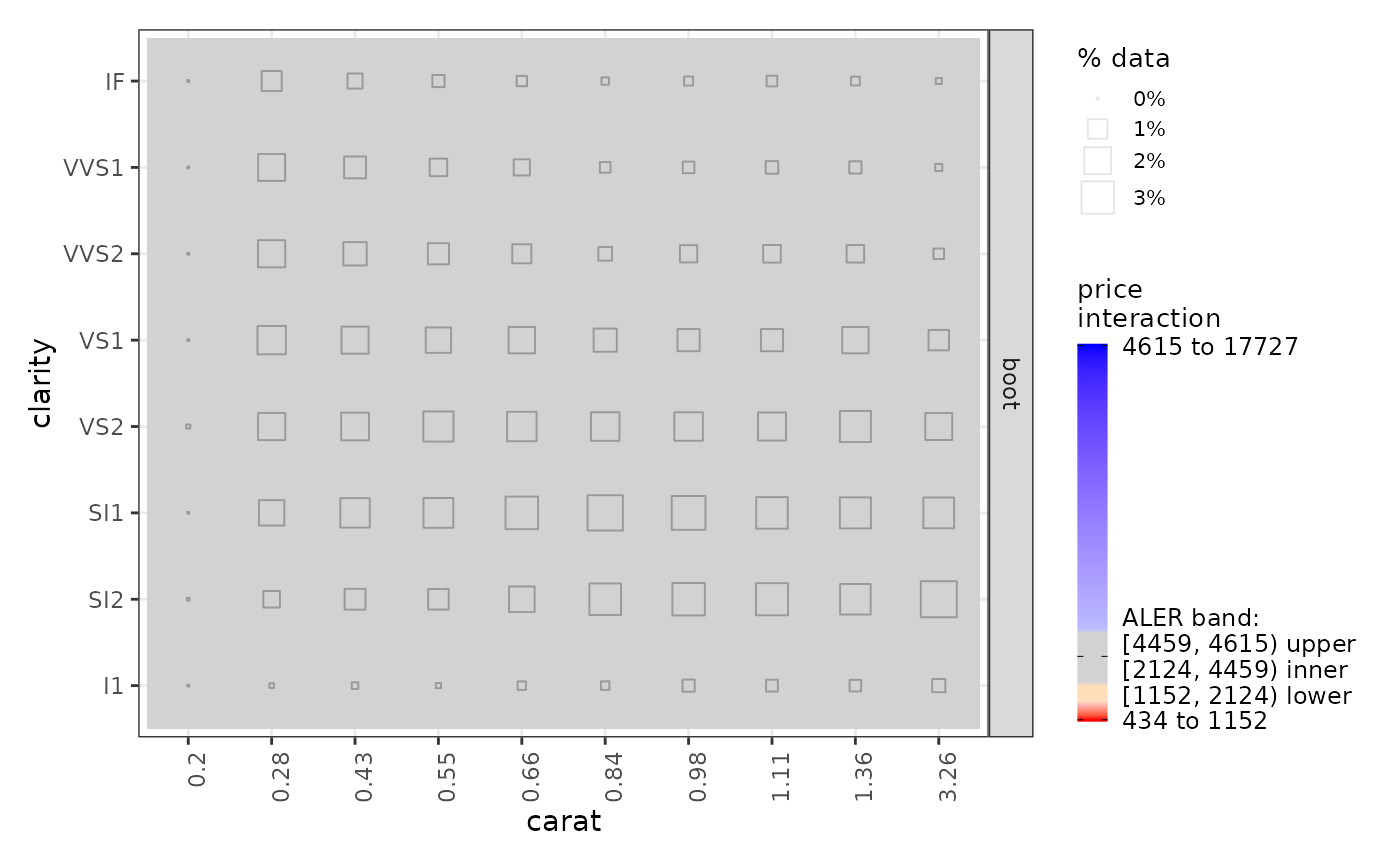 # Extract specific plots (as lists of ggplot objects)
get(ale_plots, 'carat') # extract a specific 1D plot
# Extract specific plots (as lists of ggplot objects)
get(ale_plots, 'carat') # extract a specific 1D plot
 get(ale_plots, 'carat:clarity') # extract a specific 2D plot
get(ale_plots, 'carat:clarity') # extract a specific 2D plot
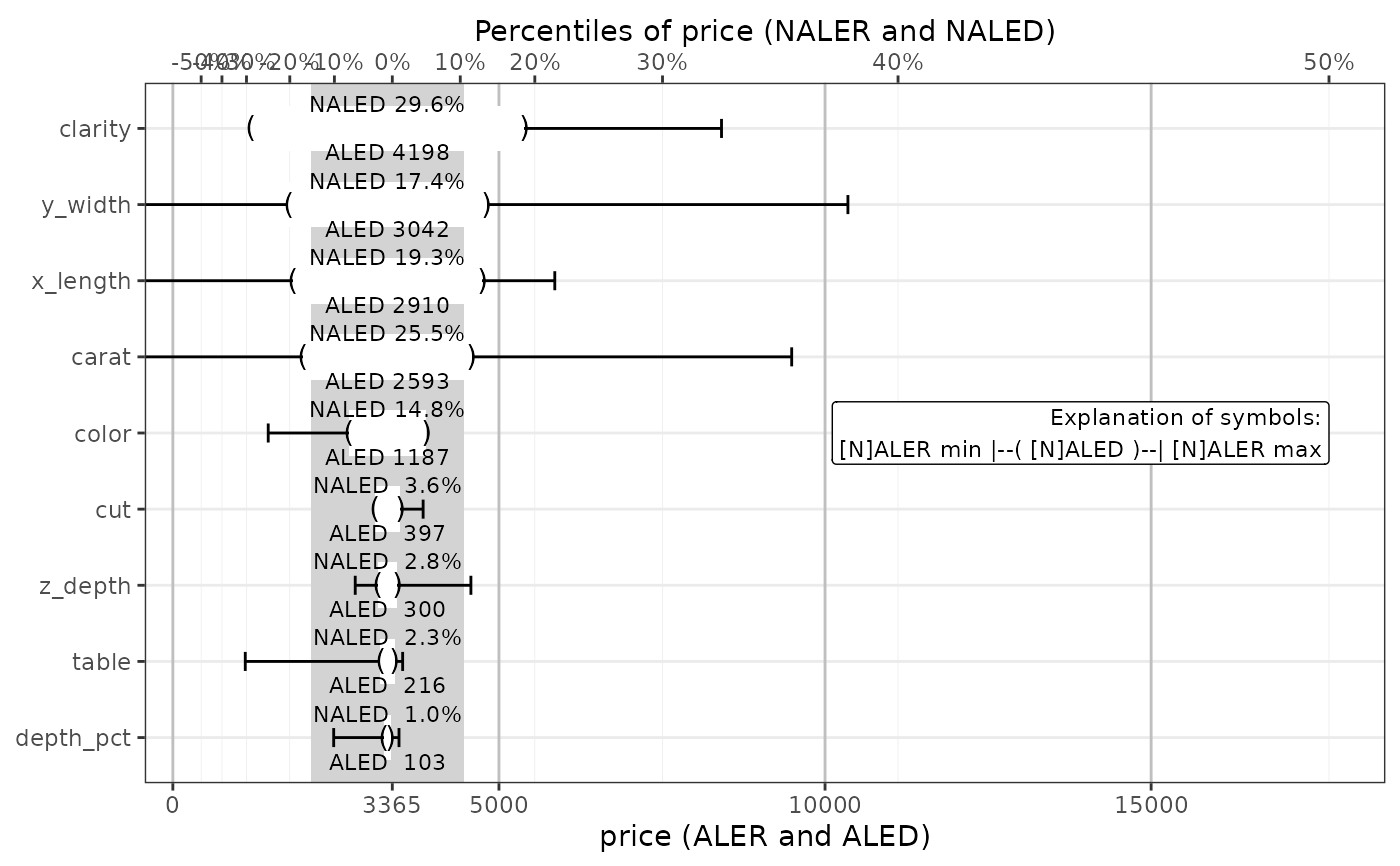
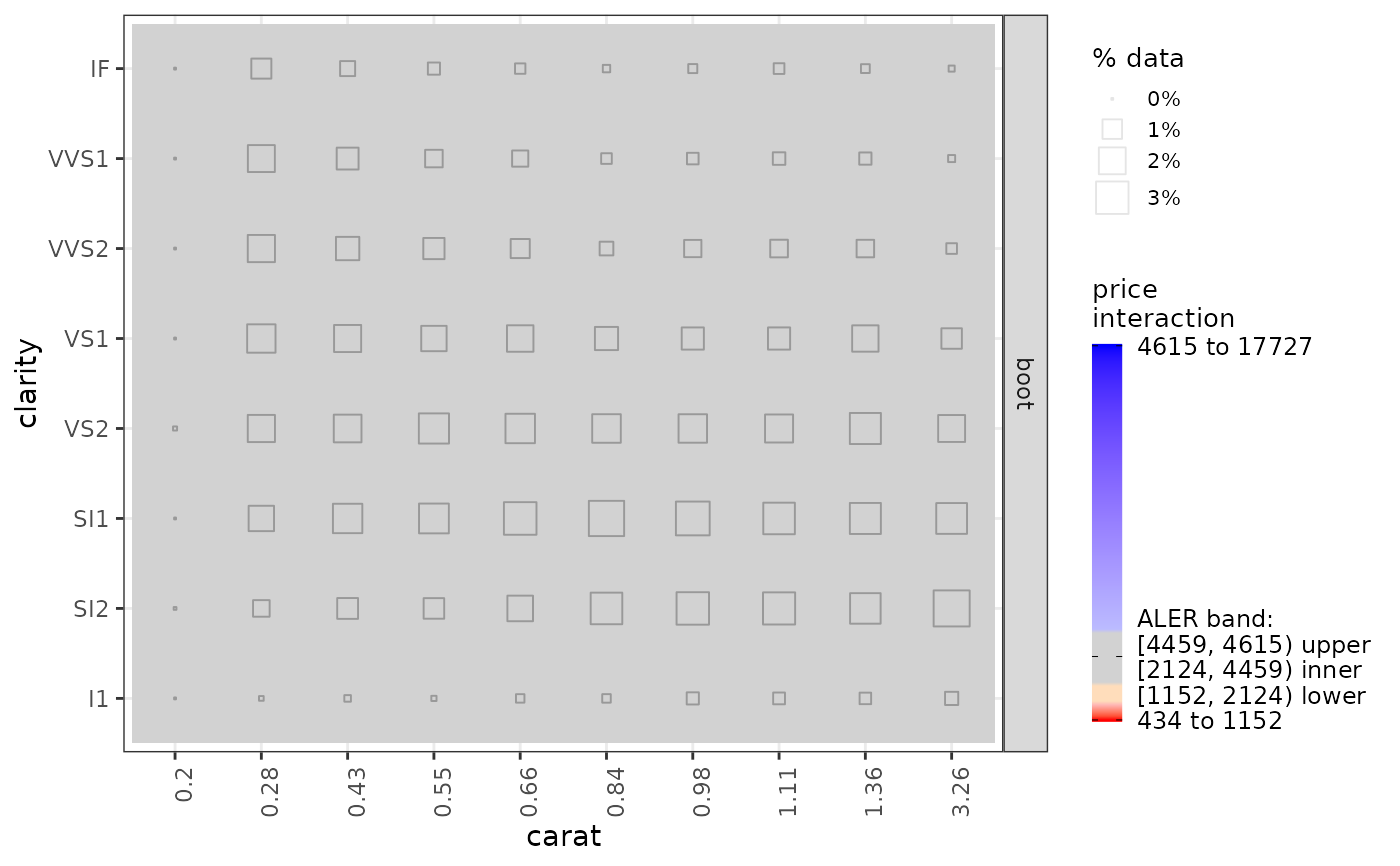 get(ale_plots, type = 'effect') # ALE effects plot
#> `height` was translated to `width`.
get(ale_plots, type = 'effect') # ALE effects plot
#> `height` was translated to `width`.
 # See help(get.ALEPlots) for more options, such as for categorical plots
# If the predict function you want does not work automatically, you may
# define a custom predict function. It must return a single numeric vector.
custom_predict <- function(object, newdata, type = pred_type) {
predict(object, newdata, type = type, se.fit = TRUE)$fit
}
ale_gam_diamonds_custom <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_gam_diamonds_custom.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
ALE(
gam_diamonds,
pred_fun = custom_predict,
pred_type = 'link'
)
}
)
# saveRDS(ale_gam_diamonds_custom, file.choose())
# Plot the ALE data
plot(ale_gam_diamonds_custom)
# See help(get.ALEPlots) for more options, such as for categorical plots
# If the predict function you want does not work automatically, you may
# define a custom predict function. It must return a single numeric vector.
custom_predict <- function(object, newdata, type = pred_type) {
predict(object, newdata, type = type, se.fit = TRUE)$fit
}
ale_gam_diamonds_custom <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_gam_diamonds_custom.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
ALE(
gam_diamonds,
pred_fun = custom_predict,
pred_type = 'link'
)
}
)
# saveRDS(ale_gam_diamonds_custom, file.choose())
# Plot the ALE data
plot(ale_gam_diamonds_custom)
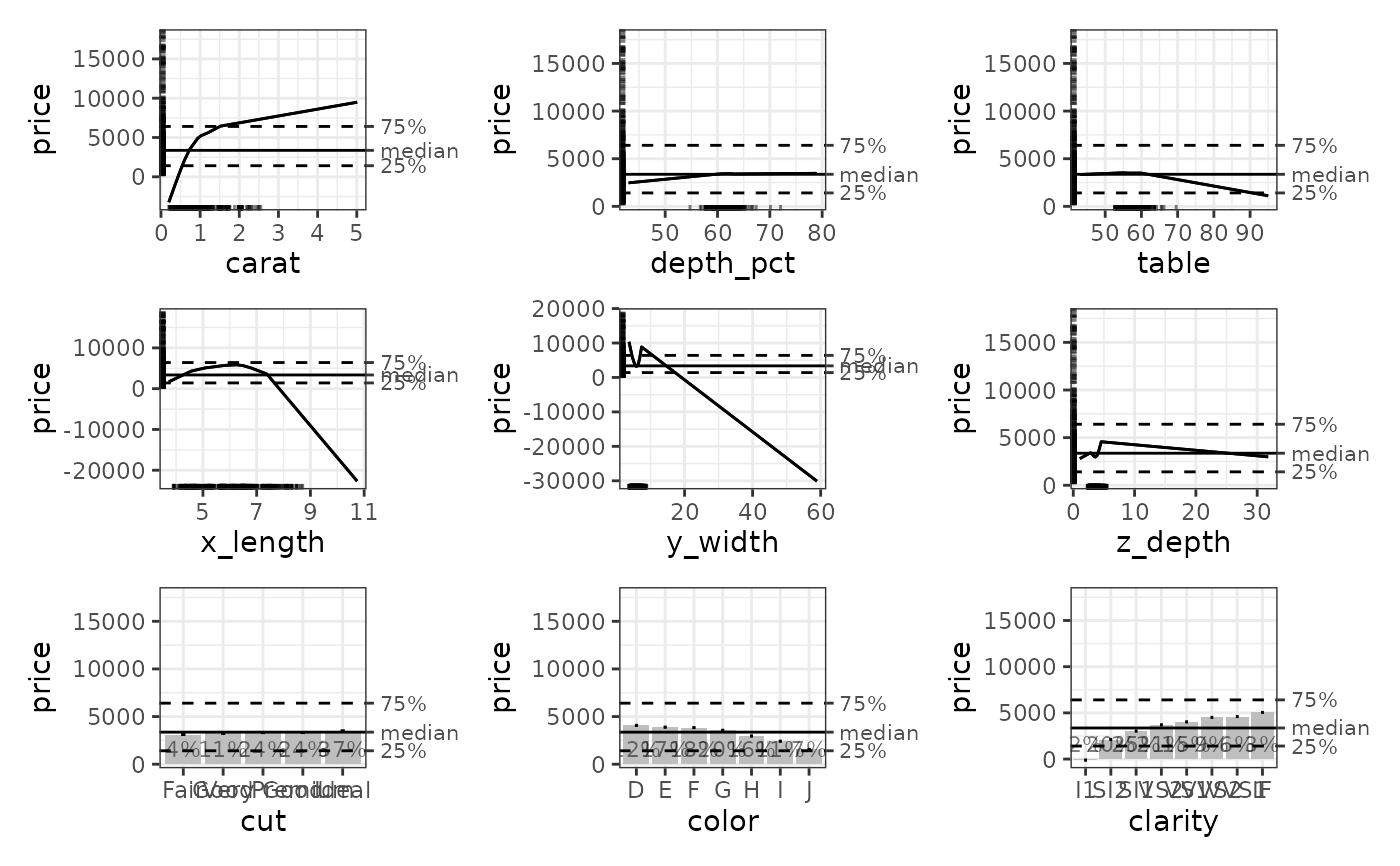 # How to retrieve specific types of ALE data from an ALE object.
ale_diamonds_with_boot_data <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_diamonds_with_boot_data.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
# For models like mgcv::gam that store their data,
# there is no need to specify the data argument.
ALE(
gam_diamonds,
# For detailed options for x_cols, see examples at resolve_x_cols()
x_cols = ~ carat + cut + clarity + carat:clarity + color:depth_pct,
output_boot_data = TRUE,
boot_it = 10 # just for demonstration
)
}
)
# saveRDS(ale_diamonds_with_boot_data, file.choose())
# See ?get.ALE for details on the various kinds of data that may be retrieved.
get(ale_diamonds_with_boot_data, ~ carat + color:depth_pct) # default ALE data
#> $d1
#> $d1$carat
#> # A tibble: 10 × 7
#> carat.ceil .n .y .y_lo .y_mean .y_median .y_hi
#> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.2 7 -3234. -3234. -3234. -3234. -3234.
#> 2 0.36 4737 -1009. -1009. -1009. -1009. -1009.
#> 3 0.5 4431 869. 869. 869. 869. 869.
#> 4 0.6 4100 2101. 2101. 2101. 2101. 2101.
#> 5 0.73 4442 3467. 3467. 3467. 3467. 3467.
#> 6 0.94 4406 4910. 4910. 4910. 4910. 4910.
#> 7 1.03 4535 5244. 5244. 5244. 5244. 5244.
#> 8 1.2 4370 5604. 5604. 5604. 5604. 5604.
#> 9 1.52 4605 6446. 6446. 6446. 6446. 6446.
#> 10 5.01 4106 9489. 9489. 9489. 9489. 9489.
#>
#>
#> $d2
#> $d2$`color:depth_pct`
#> # A tibble: 70 × 8
#> color.bin depth_pct.ceil .n .y .y_lo .y_mean .y_median .y_hi
#> <ord> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 D 43 0 3365 3365 3365 3365 3365
#> 2 E 43 0 3365 3365 3365 3365 3365
#> 3 F 43 0 3365 3365 3365 3365 3365
#> 4 G 43 1 3365 3365 3365 3365 3365
#> 5 H 43 0 3365 3365 3365 3365 3365
#> 6 I 43 0 3365 3365 3365 3365 3365
#> 7 J 43 1 3365 3365 3365 3365 3365
#> 8 D 60 627 3365 3365 3365 3365 3365
#> 9 E 60 940 3365 3365 3365 3365 3365
#> 10 F 60 871 3365 3365 3365 3365 3365
#> # ℹ 60 more rows
#>
#>
get(ale_diamonds_with_boot_data, what = 'boot_data') # raw bootstrap data
#> $d1
#> $d1$carat
#> # A tibble: 110 × 6
#> .it carat .y_composite .n .y_distinct .y
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0.2 -3234. 7 -3234. -3234.
#> 2 0 0.36 -1009. 4737 -1009. -1009.
#> 3 0 0.5 869. 4431 869. 869.
#> 4 0 0.6 2101. 4100 2101. 2101.
#> 5 0 0.73 3467. 4442 3467. 3467.
#> 6 0 0.94 4910. 4406 4910. 4910.
#> 7 0 1.03 5244. 4535 5244. 5244.
#> 8 0 1.2 5604. 4370 5604. 5604.
#> 9 0 1.52 6446. 4605 6446. 6446.
#> 10 0 5.01 9489. 4106 9489. 9489.
#> # ℹ 100 more rows
#>
#> $d1$cut
#> # A tibble: 55 × 6
#> .it cut .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 Fair 3110. 1492 3110. 3110.
#> 2 0 Good 3245. 4173 3245. 3245.
#> 3 0 Very Good 3314. 9714 3314. 3314.
#> 4 0 Premium 3318. 9657 3318. 3318.
#> 5 0 Ideal 3489. 14703 3489. 3489.
#> 6 1 Fair 3361. 1492 3361. 3361.
#> 7 1 Good 3615. 4173 3615. 3615.
#> 8 1 Very Good 3733. 9714 3733. 3733.
#> 9 1 Premium 3785. 9657 3785. 3785.
#> 10 1 Ideal 3831. 14703 3831. 3831.
#> # ℹ 45 more rows
#>
#> $d1$clarity
#> # A tibble: 88 × 6
#> .it clarity .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 I1 -109. 704 -109. -109.
#> 2 0 SI2 2114. 7916 2114. 2114.
#> 3 0 SI1 3035. 9857 3035. 3035.
#> 4 0 VS2 3702. 8227 3702. 3702.
#> 5 0 VS1 4020. 6007 4020. 4020.
#> 6 0 VVS2 4517. 3463 4517. 4517.
#> 7 0 VVS1 4594. 2413 4594. 4594.
#> 8 0 IF 5052. 1152 5052. 5052.
#> 9 1 I1 3356. 704 3356. 3356.
#> 10 1 SI2 6830. 7916 6830. 6830.
#> # ℹ 78 more rows
#>
#>
#> $d2
#> $d2$`carat:clarity`
#> # A tibble: 880 × 7
#> .it carat clarity .y_composite .n .y_distinct .y
#> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0.2 I1 3365 0 3365 3365
#> 2 0 0.36 I1 3365 10 3365 3365
#> 3 0 0.5 I1 3365 28 3365 3365
#> 4 0 0.6 I1 3365 14 3365 3365
#> 5 0 0.73 I1 3365 55 3365 3365
#> 6 0 0.94 I1 3365 56 3365 3365
#> 7 0 1.03 I1 3365 134 3365 3365
#> 8 0 1.2 I1 3365 125 3365 3365
#> 9 0 1.52 I1 3365 119 3365 3365
#> 10 0 5.01 I1 3365 163 3365. 3365.
#> # ℹ 870 more rows
#>
#> $d2$`color:depth_pct`
#> # A tibble: 770 × 7
#> .it color depth_pct .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 D 43 3365 0 3365 3365
#> 2 0 E 43 3365 0 3365 3365
#> 3 0 F 43 3365 0 3365 3365
#> 4 0 G 43 3365 1 3365 3365
#> 5 0 H 43 3365 0 3365 3365
#> 6 0 I 43 3365 0 3365 3365
#> 7 0 J 43 3365 1 3365 3365
#> 8 0 D 60 3365 627 3365 3365
#> 9 0 E 60 3365 940 3365 3365
#> 10 0 F 60 3365 871 3365 3365
#> # ℹ 760 more rows
#>
#>
get(ale_diamonds_with_boot_data, stats = 'estimate') # summary statistics
#> $d1
#> # A tibble: 3 × 7
#> term aled aler_min aler_max naled naler_min naler_max
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat 2592. -6599. 6124. 25.5 -50 36.2
#> 2 cut 398. 0.585 474. 3.59 0.00453 4.31
#> 3 clarity 4185. -16.3 5038. 29.5 -0.174 33.0
#>
#> $d2
#> # A tibble: 2 × 7
#> term aled aler_min aler_max naled naler_min naler_max
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat:clarity 1.08e-12 -6.27e-12 2.43e-12 0 0 0
#> 2 color:depth_pct 6.69e-13 -1.27e-12 6.74e-13 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = c('aled', 'naled'))
#> $d1
#> # A tibble: 6 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 2592. 0 carat 2583. 2592. 2592. 2597.
#> 2 naled 25.5 0 carat 25.4 25.5 25.5 25.5
#> 3 aled 398. 0 cut 392. 398. 398. 403.
#> 4 naled 3.59 0 cut 3.54 3.59 3.60 3.64
#> 5 aled 4185. 0 clarity 4081. 4185. 4195. 4252.
#> 6 naled 29.5 0 clarity 29.1 29.5 29.6 29.8
#>
#> $d2
#> # A tibble: 4 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 1.08e-12 1 carat:clarity 7.67e-13 1.08e-12 1.08e-12 1.43e-12
#> 2 naled 0 1 carat:clarity 0 0 0 0
#> 3 aled 6.69e-13 1 color:depth_p… 1.80e-13 6.69e-13 5.33e-13 1.56e-12
#> 4 naled 0 1 color:depth_p… 0 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = 'all')
#> $d1
#> # A tibble: 18 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 2592. 0 carat 2583. 2.59e+3 2.59e+3 2.60e+3
#> 2 aler_min -6599. 0 carat -6599. -6.60e+3 -6.60e+3 -6.60e+3
#> 3 aler_max 6124. 0 carat 6124. 6.12e+3 6.12e+3 6.12e+3
#> 4 naled 25.5 0 carat 25.4 2.55e+1 2.55e+1 2.55e+1
#> 5 naler_min -50 0 carat -50 -5 e+1 -5 e+1 -5 e+1
#> 6 naler_max 36.2 0 carat 36.2 3.62e+1 3.62e+1 3.62e+1
#> 7 aled 398. 0 cut 392. 3.98e+2 3.98e+2 4.03e+2
#> 8 aler_min 0.585 1 cut -3.47 5.85e-1 1.23e-1 5.89e+0
#> 9 aler_max 474. 0.14 cut 467. 4.74e+2 4.74e+2 4.79e+2
#> 10 naled 3.59 0 cut 3.54 3.59e+0 3.60e+0 3.64e+0
#> 11 naler_min 0.00453 1 cut -0.0352 4.53e-3 0 4.86e-2
#> 12 naler_max 4.31 0.13 cut 4.26 4.31e+0 4.32e+0 4.36e+0
#> 13 aled 4185. 0 clarity 4081. 4.18e+3 4.20e+3 4.25e+3
#> 14 aler_min -16.3 0.96 clarity -129. -1.63e+1 1.11e+0 3.68e+1
#> 15 aler_max 5038. 0 clarity 4939. 5.04e+3 5.04e+3 5.11e+3
#> 16 naled 29.5 0 clarity 29.1 2.95e+1 2.96e+1 2.98e+1
#> 17 naler_min -0.174 0.96 clarity -1.28 -1.74e-1 -5.05e-3 3.42e-1
#> 18 naler_max 33.0 0 clarity 32.7 3.30e+1 3.30e+1 3.32e+1
#>
#> $d2
#> # A tibble: 12 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 1.08e-12 1 carat:cl… 7.67e-13 1.08e-12 1.08e-12 1.43e-12
#> 2 aler_min -6.27e-12 1 carat:cl… -7.85e-12 -6.27e-12 -6.09e-12 -5.01e-12
#> 3 aler_max 2.43e-12 1 carat:cl… 1.76e-12 2.43e-12 2.41e-12 3.37e-12
#> 4 naled 0 1 carat:cl… 0 0 0 0
#> 5 naler_min 0 1 carat:cl… 0 0 0 0
#> 6 naler_max 0 1 carat:cl… 0 0 0 0
#> 7 aled 6.69e-13 1 color:de… 1.80e-13 6.69e-13 5.33e-13 1.56e-12
#> 8 aler_min -1.27e-12 1 color:de… -2.75e-12 -1.27e-12 -1.35e-12 -3.14e-13
#> 9 aler_max 6.74e-13 1 color:de… 1.75e-13 6.74e-13 5.38e-13 1.34e-12
#> 10 naled 0 1 color:de… 0 0 0 0
#> 11 naler_min 0 1 color:de… 0 0 0 0
#> 12 naler_max 0 1 color:de… 0 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = 'conf_regions')
#> ! Note that confidence regions are not reliable with fewer than 100 bootstrap
#> iterations or p-values based on fewer than 100 random iterations.
#> ℹ There are 10 bootstrap iterations.
#> ℹ p-values are based on 100 iterations.
#> $d1
#> # A tibble: 16 × 12
#> term x start_x end_x x_span_pct n pct y start_y end_y trend
#> <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat NA 0.2 0.6 8.32 13275 33.4 NA -3234. 2101. 3.71
#> 2 carat NA 0.73 0.73 0 4442 11.2 NA 3467. 3467. 0
#> 3 carat NA 0.94 5.01 84.6 22022 55.4 NA 4910. 9489. 0.313
#> 4 cut Fair NA NA NA 1492 3.75 3342. NA NA NA
#> 5 cut Good NA NA NA 4173 10.5 3587. NA NA NA
#> 6 cut Very… NA NA NA 9714 24.4 3702. NA NA NA
#> 7 cut Prem… NA NA NA 9657 24.3 3748. NA NA NA
#> 8 cut Ideal NA NA NA 14703 37.0 3807. NA NA NA
#> 9 clarity I1 NA NA NA 704 1.77 3034. NA NA NA
#> 10 clarity SI2 NA NA NA 7916 19.9 6392. NA NA NA
#> 11 clarity SI1 NA NA NA 9857 24.8 7610. NA NA NA
#> 12 clarity VS2 NA NA NA 8227 20.7 7975. NA NA NA
#> 13 clarity VS1 NA NA NA 6007 15.1 7695. NA NA NA
#> 14 clarity VVS2 NA NA NA 3463 8.71 7144. NA NA NA
#> 15 clarity VVS1 NA NA NA 2413 6.07 6101. NA NA NA
#> 16 clarity IF NA NA NA 1152 2.90 5045. NA NA NA
#> # ℹ 1 more variable: aler_band <ord>
#>
#> $d2
#> # A tibble: 45 × 8
#> term1 x1 term2 x2 aler_band n pct y
#> <chr> <chr> <chr> <chr> <ord> <int> <dbl> <dbl>
#> 1 carat [0.2,0.6] clarity I1 overlap 52 0.131 3365
#> 2 carat (0.6,1.03] clarity I1 overlap 245 0.617 3365
#> 3 carat (1.03,5.01] clarity I1 overlap 407 1.02 3365
#> 4 carat [0.2,0.6] clarity SI2 overlap 1180 2.97 3365
#> 5 carat (0.6,1.03] clarity SI2 overlap 3036 7.64 3365
#> 6 carat (1.03,5.01] clarity SI2 overlap 3700 9.31 3365
#> 7 carat [0.2,0.6] clarity SI1 overlap 2665 6.71 3365
#> 8 carat (0.6,1.03] clarity SI1 overlap 3921 9.87 3365
#> 9 carat (1.03,5.01] clarity SI1 overlap 3271 8.23 3365
#> 10 carat [0.2,0.6] clarity VS2 overlap 2693 6.78 3365
#> # ℹ 35 more rows
#>
get(ale_diamonds_with_boot_data, stats = 'conf_sig')
#> ! Note that confidence regions are not reliable with fewer than 100 bootstrap
#> iterations or p-values based on fewer than 100 random iterations.
#> ℹ There are 10 bootstrap iterations.
#> ℹ p-values are based on 100 iterations.
#> # A tibble: 11 × 12
#> term x start_x end_x x_span_pct n pct y start_y end_y trend
#> <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat NA 0.2 0.6 8.32 13275 33.4 NA -3234. 2101. 3.71
#> 2 carat NA 0.73 0.73 0 4442 11.2 NA 3467. 3467. 0
#> 3 carat NA 0.94 5.01 84.6 22022 55.4 NA 4910. 9489. 0.313
#> 4 clarity I1 NA NA NA 704 1.77 3034. NA NA NA
#> 5 clarity SI2 NA NA NA 7916 19.9 6392. NA NA NA
#> 6 clarity SI1 NA NA NA 9857 24.8 7610. NA NA NA
#> 7 clarity VS2 NA NA NA 8227 20.7 7975. NA NA NA
#> 8 clarity VS1 NA NA NA 6007 15.1 7695. NA NA NA
#> 9 clarity VVS2 NA NA NA 3463 8.71 7144. NA NA NA
#> 10 clarity VVS1 NA NA NA 2413 6.07 6101. NA NA NA
#> 11 clarity IF NA NA NA 1152 2.90 5045. NA NA NA
#> # ℹ 1 more variable: aler_band <ord>
# }
# How to retrieve specific types of ALE data from an ALE object.
ale_diamonds_with_boot_data <- retrieve_rds(
# For speed, load a pre-created object by default.
c(serialized_objects_site, 'ale_diamonds_with_boot_data.0.5.2.rds'),
{
# To run the code yourself, execute this code block directly.
# For models like mgcv::gam that store their data,
# there is no need to specify the data argument.
ALE(
gam_diamonds,
# For detailed options for x_cols, see examples at resolve_x_cols()
x_cols = ~ carat + cut + clarity + carat:clarity + color:depth_pct,
output_boot_data = TRUE,
boot_it = 10 # just for demonstration
)
}
)
# saveRDS(ale_diamonds_with_boot_data, file.choose())
# See ?get.ALE for details on the various kinds of data that may be retrieved.
get(ale_diamonds_with_boot_data, ~ carat + color:depth_pct) # default ALE data
#> $d1
#> $d1$carat
#> # A tibble: 10 × 7
#> carat.ceil .n .y .y_lo .y_mean .y_median .y_hi
#> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.2 7 -3234. -3234. -3234. -3234. -3234.
#> 2 0.36 4737 -1009. -1009. -1009. -1009. -1009.
#> 3 0.5 4431 869. 869. 869. 869. 869.
#> 4 0.6 4100 2101. 2101. 2101. 2101. 2101.
#> 5 0.73 4442 3467. 3467. 3467. 3467. 3467.
#> 6 0.94 4406 4910. 4910. 4910. 4910. 4910.
#> 7 1.03 4535 5244. 5244. 5244. 5244. 5244.
#> 8 1.2 4370 5604. 5604. 5604. 5604. 5604.
#> 9 1.52 4605 6446. 6446. 6446. 6446. 6446.
#> 10 5.01 4106 9489. 9489. 9489. 9489. 9489.
#>
#>
#> $d2
#> $d2$`color:depth_pct`
#> # A tibble: 70 × 8
#> color.bin depth_pct.ceil .n .y .y_lo .y_mean .y_median .y_hi
#> <ord> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 D 43 0 3365 3365 3365 3365 3365
#> 2 E 43 0 3365 3365 3365 3365 3365
#> 3 F 43 0 3365 3365 3365 3365 3365
#> 4 G 43 1 3365 3365 3365 3365 3365
#> 5 H 43 0 3365 3365 3365 3365 3365
#> 6 I 43 0 3365 3365 3365 3365 3365
#> 7 J 43 1 3365 3365 3365 3365 3365
#> 8 D 60 627 3365 3365 3365 3365 3365
#> 9 E 60 940 3365 3365 3365 3365 3365
#> 10 F 60 871 3365 3365 3365 3365 3365
#> # ℹ 60 more rows
#>
#>
get(ale_diamonds_with_boot_data, what = 'boot_data') # raw bootstrap data
#> $d1
#> $d1$carat
#> # A tibble: 110 × 6
#> .it carat .y_composite .n .y_distinct .y
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0.2 -3234. 7 -3234. -3234.
#> 2 0 0.36 -1009. 4737 -1009. -1009.
#> 3 0 0.5 869. 4431 869. 869.
#> 4 0 0.6 2101. 4100 2101. 2101.
#> 5 0 0.73 3467. 4442 3467. 3467.
#> 6 0 0.94 4910. 4406 4910. 4910.
#> 7 0 1.03 5244. 4535 5244. 5244.
#> 8 0 1.2 5604. 4370 5604. 5604.
#> 9 0 1.52 6446. 4605 6446. 6446.
#> 10 0 5.01 9489. 4106 9489. 9489.
#> # ℹ 100 more rows
#>
#> $d1$cut
#> # A tibble: 55 × 6
#> .it cut .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 Fair 3110. 1492 3110. 3110.
#> 2 0 Good 3245. 4173 3245. 3245.
#> 3 0 Very Good 3314. 9714 3314. 3314.
#> 4 0 Premium 3318. 9657 3318. 3318.
#> 5 0 Ideal 3489. 14703 3489. 3489.
#> 6 1 Fair 3361. 1492 3361. 3361.
#> 7 1 Good 3615. 4173 3615. 3615.
#> 8 1 Very Good 3733. 9714 3733. 3733.
#> 9 1 Premium 3785. 9657 3785. 3785.
#> 10 1 Ideal 3831. 14703 3831. 3831.
#> # ℹ 45 more rows
#>
#> $d1$clarity
#> # A tibble: 88 × 6
#> .it clarity .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 I1 -109. 704 -109. -109.
#> 2 0 SI2 2114. 7916 2114. 2114.
#> 3 0 SI1 3035. 9857 3035. 3035.
#> 4 0 VS2 3702. 8227 3702. 3702.
#> 5 0 VS1 4020. 6007 4020. 4020.
#> 6 0 VVS2 4517. 3463 4517. 4517.
#> 7 0 VVS1 4594. 2413 4594. 4594.
#> 8 0 IF 5052. 1152 5052. 5052.
#> 9 1 I1 3356. 704 3356. 3356.
#> 10 1 SI2 6830. 7916 6830. 6830.
#> # ℹ 78 more rows
#>
#>
#> $d2
#> $d2$`carat:clarity`
#> # A tibble: 880 × 7
#> .it carat clarity .y_composite .n .y_distinct .y
#> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 0 0.2 I1 3365 0 3365 3365
#> 2 0 0.36 I1 3365 10 3365 3365
#> 3 0 0.5 I1 3365 28 3365 3365
#> 4 0 0.6 I1 3365 14 3365 3365
#> 5 0 0.73 I1 3365 55 3365 3365
#> 6 0 0.94 I1 3365 56 3365 3365
#> 7 0 1.03 I1 3365 134 3365 3365
#> 8 0 1.2 I1 3365 125 3365 3365
#> 9 0 1.52 I1 3365 119 3365 3365
#> 10 0 5.01 I1 3365 163 3365. 3365.
#> # ℹ 870 more rows
#>
#> $d2$`color:depth_pct`
#> # A tibble: 770 × 7
#> .it color depth_pct .y_composite .n .y_distinct .y
#> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 D 43 3365 0 3365 3365
#> 2 0 E 43 3365 0 3365 3365
#> 3 0 F 43 3365 0 3365 3365
#> 4 0 G 43 3365 1 3365 3365
#> 5 0 H 43 3365 0 3365 3365
#> 6 0 I 43 3365 0 3365 3365
#> 7 0 J 43 3365 1 3365 3365
#> 8 0 D 60 3365 627 3365 3365
#> 9 0 E 60 3365 940 3365 3365
#> 10 0 F 60 3365 871 3365 3365
#> # ℹ 760 more rows
#>
#>
get(ale_diamonds_with_boot_data, stats = 'estimate') # summary statistics
#> $d1
#> # A tibble: 3 × 7
#> term aled aler_min aler_max naled naler_min naler_max
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat 2592. -6599. 6124. 25.5 -50 36.2
#> 2 cut 398. 0.585 474. 3.59 0.00453 4.31
#> 3 clarity 4185. -16.3 5038. 29.5 -0.174 33.0
#>
#> $d2
#> # A tibble: 2 × 7
#> term aled aler_min aler_max naled naler_min naler_max
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat:clarity 1.08e-12 -6.27e-12 2.43e-12 0 0 0
#> 2 color:depth_pct 6.69e-13 -1.27e-12 6.74e-13 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = c('aled', 'naled'))
#> $d1
#> # A tibble: 6 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 2592. 0 carat 2583. 2592. 2592. 2597.
#> 2 naled 25.5 0 carat 25.4 25.5 25.5 25.5
#> 3 aled 398. 0 cut 392. 398. 398. 403.
#> 4 naled 3.59 0 cut 3.54 3.59 3.60 3.64
#> 5 aled 4185. 0 clarity 4081. 4185. 4195. 4252.
#> 6 naled 29.5 0 clarity 29.1 29.5 29.6 29.8
#>
#> $d2
#> # A tibble: 4 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 1.08e-12 1 carat:clarity 7.67e-13 1.08e-12 1.08e-12 1.43e-12
#> 2 naled 0 1 carat:clarity 0 0 0 0
#> 3 aled 6.69e-13 1 color:depth_p… 1.80e-13 6.69e-13 5.33e-13 1.56e-12
#> 4 naled 0 1 color:depth_p… 0 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = 'all')
#> $d1
#> # A tibble: 18 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 2592. 0 carat 2583. 2.59e+3 2.59e+3 2.60e+3
#> 2 aler_min -6599. 0 carat -6599. -6.60e+3 -6.60e+3 -6.60e+3
#> 3 aler_max 6124. 0 carat 6124. 6.12e+3 6.12e+3 6.12e+3
#> 4 naled 25.5 0 carat 25.4 2.55e+1 2.55e+1 2.55e+1
#> 5 naler_min -50 0 carat -50 -5 e+1 -5 e+1 -5 e+1
#> 6 naler_max 36.2 0 carat 36.2 3.62e+1 3.62e+1 3.62e+1
#> 7 aled 398. 0 cut 392. 3.98e+2 3.98e+2 4.03e+2
#> 8 aler_min 0.585 1 cut -3.47 5.85e-1 1.23e-1 5.89e+0
#> 9 aler_max 474. 0.14 cut 467. 4.74e+2 4.74e+2 4.79e+2
#> 10 naled 3.59 0 cut 3.54 3.59e+0 3.60e+0 3.64e+0
#> 11 naler_min 0.00453 1 cut -0.0352 4.53e-3 0 4.86e-2
#> 12 naler_max 4.31 0.13 cut 4.26 4.31e+0 4.32e+0 4.36e+0
#> 13 aled 4185. 0 clarity 4081. 4.18e+3 4.20e+3 4.25e+3
#> 14 aler_min -16.3 0.96 clarity -129. -1.63e+1 1.11e+0 3.68e+1
#> 15 aler_max 5038. 0 clarity 4939. 5.04e+3 5.04e+3 5.11e+3
#> 16 naled 29.5 0 clarity 29.1 2.95e+1 2.96e+1 2.98e+1
#> 17 naler_min -0.174 0.96 clarity -1.28 -1.74e-1 -5.05e-3 3.42e-1
#> 18 naler_max 33.0 0 clarity 32.7 3.30e+1 3.30e+1 3.32e+1
#>
#> $d2
#> # A tibble: 12 × 8
#> statistic estimate p.value term conf.low mean median conf.high
#> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 aled 1.08e-12 1 carat:cl… 7.67e-13 1.08e-12 1.08e-12 1.43e-12
#> 2 aler_min -6.27e-12 1 carat:cl… -7.85e-12 -6.27e-12 -6.09e-12 -5.01e-12
#> 3 aler_max 2.43e-12 1 carat:cl… 1.76e-12 2.43e-12 2.41e-12 3.37e-12
#> 4 naled 0 1 carat:cl… 0 0 0 0
#> 5 naler_min 0 1 carat:cl… 0 0 0 0
#> 6 naler_max 0 1 carat:cl… 0 0 0 0
#> 7 aled 6.69e-13 1 color:de… 1.80e-13 6.69e-13 5.33e-13 1.56e-12
#> 8 aler_min -1.27e-12 1 color:de… -2.75e-12 -1.27e-12 -1.35e-12 -3.14e-13
#> 9 aler_max 6.74e-13 1 color:de… 1.75e-13 6.74e-13 5.38e-13 1.34e-12
#> 10 naled 0 1 color:de… 0 0 0 0
#> 11 naler_min 0 1 color:de… 0 0 0 0
#> 12 naler_max 0 1 color:de… 0 0 0 0
#>
get(ale_diamonds_with_boot_data, stats = 'conf_regions')
#> ! Note that confidence regions are not reliable with fewer than 100 bootstrap
#> iterations or p-values based on fewer than 100 random iterations.
#> ℹ There are 10 bootstrap iterations.
#> ℹ p-values are based on 100 iterations.
#> $d1
#> # A tibble: 16 × 12
#> term x start_x end_x x_span_pct n pct y start_y end_y trend
#> <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat NA 0.2 0.6 8.32 13275 33.4 NA -3234. 2101. 3.71
#> 2 carat NA 0.73 0.73 0 4442 11.2 NA 3467. 3467. 0
#> 3 carat NA 0.94 5.01 84.6 22022 55.4 NA 4910. 9489. 0.313
#> 4 cut Fair NA NA NA 1492 3.75 3342. NA NA NA
#> 5 cut Good NA NA NA 4173 10.5 3587. NA NA NA
#> 6 cut Very… NA NA NA 9714 24.4 3702. NA NA NA
#> 7 cut Prem… NA NA NA 9657 24.3 3748. NA NA NA
#> 8 cut Ideal NA NA NA 14703 37.0 3807. NA NA NA
#> 9 clarity I1 NA NA NA 704 1.77 3034. NA NA NA
#> 10 clarity SI2 NA NA NA 7916 19.9 6392. NA NA NA
#> 11 clarity SI1 NA NA NA 9857 24.8 7610. NA NA NA
#> 12 clarity VS2 NA NA NA 8227 20.7 7975. NA NA NA
#> 13 clarity VS1 NA NA NA 6007 15.1 7695. NA NA NA
#> 14 clarity VVS2 NA NA NA 3463 8.71 7144. NA NA NA
#> 15 clarity VVS1 NA NA NA 2413 6.07 6101. NA NA NA
#> 16 clarity IF NA NA NA 1152 2.90 5045. NA NA NA
#> # ℹ 1 more variable: aler_band <ord>
#>
#> $d2
#> # A tibble: 45 × 8
#> term1 x1 term2 x2 aler_band n pct y
#> <chr> <chr> <chr> <chr> <ord> <int> <dbl> <dbl>
#> 1 carat [0.2,0.6] clarity I1 overlap 52 0.131 3365
#> 2 carat (0.6,1.03] clarity I1 overlap 245 0.617 3365
#> 3 carat (1.03,5.01] clarity I1 overlap 407 1.02 3365
#> 4 carat [0.2,0.6] clarity SI2 overlap 1180 2.97 3365
#> 5 carat (0.6,1.03] clarity SI2 overlap 3036 7.64 3365
#> 6 carat (1.03,5.01] clarity SI2 overlap 3700 9.31 3365
#> 7 carat [0.2,0.6] clarity SI1 overlap 2665 6.71 3365
#> 8 carat (0.6,1.03] clarity SI1 overlap 3921 9.87 3365
#> 9 carat (1.03,5.01] clarity SI1 overlap 3271 8.23 3365
#> 10 carat [0.2,0.6] clarity VS2 overlap 2693 6.78 3365
#> # ℹ 35 more rows
#>
get(ale_diamonds_with_boot_data, stats = 'conf_sig')
#> ! Note that confidence regions are not reliable with fewer than 100 bootstrap
#> iterations or p-values based on fewer than 100 random iterations.
#> ℹ There are 10 bootstrap iterations.
#> ℹ p-values are based on 100 iterations.
#> # A tibble: 11 × 12
#> term x start_x end_x x_span_pct n pct y start_y end_y trend
#> <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 carat NA 0.2 0.6 8.32 13275 33.4 NA -3234. 2101. 3.71
#> 2 carat NA 0.73 0.73 0 4442 11.2 NA 3467. 3467. 0
#> 3 carat NA 0.94 5.01 84.6 22022 55.4 NA 4910. 9489. 0.313
#> 4 clarity I1 NA NA NA 704 1.77 3034. NA NA NA
#> 5 clarity SI2 NA NA NA 7916 19.9 6392. NA NA NA
#> 6 clarity SI1 NA NA NA 9857 24.8 7610. NA NA NA
#> 7 clarity VS2 NA NA NA 8227 20.7 7975. NA NA NA
#> 8 clarity VS1 NA NA NA 6007 15.1 7695. NA NA NA
#> 9 clarity VVS2 NA NA NA 3463 8.71 7144. NA NA NA
#> 10 clarity VVS1 NA NA NA 2413 6.07 6101. NA NA NA
#> 11 clarity IF NA NA NA 1152 2.90 5045. NA NA NA
#> # ℹ 1 more variable: aler_band <ord>
# }